
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- java 단축키
- java 상속
- java Fish
- Java 메소드
- sqld 옵티마이져
- sqld revoke
- JAVA for문
- java Animal
- sqld trigger
- sqld grant
- java 함수
- SQLD 특강
- SQL
- PLSQL
- SQLD 옵티마이저
- sqld remame
- java 로또
- SQLD 핵심포인트
- Java Cat
- SQLD 자격시험 개념정리
- sqld deny
- java string
- JAVA 연산자
- java 구구단
- java
- java 논리연산자
- java spider
- java 성별
- JAVA 제어문
- sqld 자격증
- Today
- Total
SQLD, ECLIPS, JAVA,PYTHON, NODE....
[SQLD] 자격시험 - 학습 보강사항 2 본문
2024.1.2
명령어 추가 암기.
- DISTINCT : 중복제거
- NOT EXISTS : where절의 서브쿼리에 데이터가 존재하지 않는 경우에 사용
- EXIST: where 절에서 사용하며, 서브쿼리 값이 True or False로 확인해서 존재하면 출력, 존재하지 않으면 출력값 없음. 그래서 서브쿼리의 select에 '아무거나 사용가능' 아무거나 사용해도 됨.
- Cartesian Product: JOIN 조건이 존재하지 않을때, 모든 테이블의 조합인 경우의 수를 나타낼때 사용하며
Cross Join으로 코딩 가능. - UNION: 중복된 값을 제거하고 추출.(INTERSECT과 차이)
- UNION ALL: 2개의 값을 연결(붙여주는)하는 역할만 하고 중복된 값은 제거하지 않음.
알리아스도 가장 첫번째 select문에서 사용된 알리아스만 적용됨 - INTERSECT: 교집합 처럼, 공통된 값만 추출.
EXCEPT: 공통되지 않은 값만 추출.
## 서브쿼리 사용범위
- 단일행(Single Row) 또는 복수행(Multi Row) 비교연산자와 함께 사용 가능.
- SELECT 절, FROM 절, HAVING 절, ORDER BY 절에서 사용 가능.
GROUP BY 절은 사용 불가. ----> 단, 사용하기 위해선 컬럼명을 명시해주면 사용 가능. - 서브쿼리 결과가 복수행(Multi Row) 결과를 반환하는 경우, 단일행연산자( '=' , '<=', '=>' )와 다중행 연산자( or, and)와 함께 사용 가능. 단, 서브쿼리 절 앞엔 IN 사용해야 됨( 단일행연산자 '=', '<=', '=>' 사용하면 오류발생 )
ex. select *from emp
where A IN ( select B from dept where C=5 or D = 6); -- 가능
where A = ( select B from dept where C=5 or D=6); -- 오류발생 - 연관(Correlated) 서브쿼리는 주로 where절에서 사용하며, 메인쿼리 컬럼을 포함하고 있는 형태의 서브쿼리임.
ex. select A from EMP, TAB1
where A IN ( select C from dept, TAB2 where TAB1. A = TAB2.C) -- 서브쿼리 안에서 메인쿼리(A) 포함 가능. - 다중컬럼 서브쿼리는 서브쿼리의 결과로 여러 개의 컬럼이 반환되어 메인쿼리의 조건과 동시에 비교되는 것을 의미하며, Oracle SQL의 DBMS에서만 사용할 수 있다. --> SQL Server에서는 지원하지 않는 기능임.
ex. select A from emp, TAB1
where (A,B) IN ( select C, F from dept, TAB2 where TAB1.A = TAB2.F); -- 오류 - 단일형 서브쿼리는 실행결과가 항상 1건 이하인 서브쿼리이며, '=' '=>' '>='(단일행 연산자) 만 사용 가능.
단, 서브쿼리 안에선 'IN, ALL' (다중행 비교연산자)는 사용불가. - 다중행 서브쿼리 비교연산자(IN, ALL)는 단일행 서브쿼리 비교연산자(단일행: '=' '=>' '>=' )로도 사용할 수 있다.
ex. select *from emp
where A IN (select C from DEPT where C =5); -- 가능 - 연관 서브쿼리는 주로 메인쿼리에 값을 받기 위한 목적으로 사용됨.
ex. select A from EMP, TAB1
where A IN ( select C from DEPT, TAB2 where TAB1.A = TAB2 C); - 서브쿼리는
항상메인쿼리에서 얽혀진 데이터에 대해 서브퀄리에서 해당 조건이 만족하는지 확인하는 방식은 아님.
--> 실행 순서에 따라 달라짐.
ex. select TAB1 A, TAB1 B, TAB1 C, TAB1 D, TAB2 A from EMP, TAB1, (select TOP 1 A from EMP) TAB2
where TAB1 A, TAB2, A
(연습1) 아래 쿼리에 대한 설명중 틀린 것은?
select B.사원번호,
B.사원명,
A.부서번호,
A.부서명,
(select count(*)
from 부양가족 Y
where Y.사원번호=B.사원번호) as 부양가족수
from 부서 A, (select * from 사원
where 입사년도 = '2024' B )
where A.부서번호 = B.부서번호
and EXIST ( select 1 from 사원 X
where X.부서번호 = A.부서번호);- 다중행 연관 서브쿼리(where절에서 사용), 단일행 서브쿼리(select절에서 사용), Inline View(from절에 서브쿼리가 사용될 때 인라인뷰라고 함)가 사용되었다. // 맞음
- select절에서 사용된 섭쿼리는 스칼라 서브쿼리라고도 하며, 이런 형태의 서브쿼리는 JOIN으로 동일한 결과를 추출할 수 있다. // 맞음
- where 절의 서브퀄리에 사원 테이블 검색 조건으로 입사년도 조건을 from절의 서브쿼리와 동일하게 추가해야 원하는 결과를 추출할 수 있다. // 틀림
--> where절의 EXIST는 없어도 됨. - from절의 서브쿼리는 동적뷰(Dynamic view)라고도 하며, SQL 문장 중 데이터 명이 올수 있는 곳에서만 사용할 수 있다. // 맞음
(연습2) LEFT OUTER JOIN(왼쪽 행(row) 기준),
RIGHT OUTER JOIN(오른쪽 행(row) 기준),
FULL OUTER JOIN(왼쪽과 오른쪽 행(row)의 중복 값을 제외하고 전체 정렬)
수행결과, 결과가 같은 것은?
-- 1
select A.ID, B.ID
from TBL1 A, FULL OUTER JOIN TBL2 B ON A.ID = B.ID;
-- 2
select A.ID, B.ID
from TBL1 A, LEFT OUTER JOIN TBL2 B ON A.ID = B.ID
UNION
select A.ID, B.ID
from TBL1 A RIGHT OUTER JOIN TBL B ON A.ID = B.ID;
--3
select A.ID, B.ID
from TBL1 A, TBL2 B
where A.ID = B.ID
UNION ALL
select A.ID, NULL
from TBL1 A
where NOT EXIST ( select 1 from TBL2 B where A.ID=B.ID)
UNION ALL
select NULL, B,ID
from TAL2 B
where NOT EXIST( select 1 from TBL1 A where B.ID=A.ID);결과: 3종류 코드 모두 동일하게 출력 됨(1,2,3 모두 같은 값)
(연습3) 신규부서의 경우, DEPT와 EMP를 조인하되 사원이 없는 부서정보도 같이 출력하려고 할때의 코드를 기술하시오.
select E.ename, D.deptno, D.dname
from dept D left outer join emp E on D.deptno = E.deptno;정답 : left outer join (이유: 부서정보는 모두 나오되, 이름이 없는 경우만 고려하면 되므로)
(연습4) SQL 수행결과 답안을 도출하시오.
select
* from TBL1 A -- TBL1은 모두 출력
left outer join TBL2 B -- TBL2은 TBL1의 왼쪽값과 매칭
on ( A.c1 = B.c1 and B.c2 between 1 and 3) -- TBL2의 C2값 중에 TBL1과 매칭되는 값만
결과(TBL1의 Data는 모두 나오고, 그 기준으로 TBL2에서 매칭되는 2,3만 출력됨)
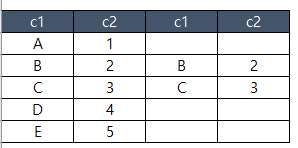
(연습5) oracle 기준으로 작성된 SQL문구를 SQL server의 ANSI 구문으로 변경하시오.
(참고) Oracle의 (+) 표시는 SQL server의 outer join을 사용할때 사용하고, +를 붙이는 반대쪽 테이블에 적용됨
select A.게시판ID, A.게시판명, count(B.게시글ID) as cnt
from 게시판 A, 게시글 B
where A.게시판ID = B.게시판ID(+)
and B.삭제여부(+) = 'N'
and A.사용여부 = 'Y'
group by A.게시판ID = A.게시판명
group by A.게시판ID;SQL server로 코딩한 결과..
select A.게시판ID, A.게시판명, count(B.게시글ID) as cnt
from 게시판 A
left outer join 게시글 B (A.게시판ID = B.게시판ID and B.삭제여부 = 'N') --(+)는 반대쪽 테이블에 연결되므로 게시글B로 join구문 사용
where A.사용여부 = 'Y' --where절 이전에 left outer join 사용
group by A.게시판ID = A.게시판명
group by A.게시판ID;
(연습6) SQL server에서 추출된 결과와 동일한 SQL을 코딩하시오.(테이블 TBL1, TBL2의 PK는 A, B)
(참고)
intersect : TBL1 데이터와 TBL2 데이터 중에서 공통된 값만 추출
except: TBL1 데이터와 TBL2 데이터 중에서 공통된(TBL1과 TBL2) 데이터와 TBL2 데이터를 제외한 데이터만 추출 됨.
select A, B
from TBL1
except -- 공통된 부분과 TBL2의 데이터도 제외 됨
select A,B
from TBL2;
--결과는 TBL1만 출력됨--틀린 코딩 1
select TBL2.A, TBL2.B
from TBL1, TBL2
where TBL1.A <> TBL2.A
and TBL1.B <> TBL2.B;
--틀린 코딩 2
select TBL1.A, TBL.B
from TBL1
where TBL1.A NOT IN ( select TBL2.A from TBL2)
and TBL1.B NOT IN ( select TBL2.B from TBL2);
--틀린 코딩3
select TBL2.A, TBL2.B
from TBL1. TBL2
where TBL1.A = TBL2.A
and TBL1.B = TBL2.B;
--정답(맞는 코딩)
select TBL1.A, TBL1.B
from TBL1
where NOT EXIST( select 'X' from TBL2
where TBL1.A = TBL2.A
and TBL1.B = TBL2.B);
(연습7) SQL이 동일한 결과를 도출하도록 코딩하시오.
(참고) INTERSECT: 테이블과 테이블 간의 공통된 값만 추출(교집합이라고 생각하면 됨)
select A.서비스ID, B.서비스명, B.서비스URL
from (select 서비스ID from 서비스
INTERSECT select 서비스ID from 서비스이용) A, 서비스 B
where A.서비스ID = B.서비스ID;-- 틀림(사용할때마다 서비스ID 개수만큼 출력되므로 틀림)
select B.서비스ID, A.서비스명, A.서비스URL
from 서비스 A, 서비스이용 B
where A.서비스ID = B.서비스ID;
-- 정답
select X.서비스ID
X.서비스명
X.서비스URL
from 서비스 X
where NOT EXISTS (select 서비스ID from 서비스
except -- Oracle에선 minus 로 코딩
select 서비스ID from 서비스이용) Y
where X.서비스ID = Y.서비스ID;
--틀립(서비스 이용한 적 없는 null데이터만 출력되므로 틀림)
select B.서비스ID
A.서비스명
A.서비스URL
from 서비스 A
left outer join 서비스이용 B on(A.서비스ID = B.서비스ID)
where B.서비스ID is null
group by B.서비스ID, A.서비스명, A.서비스URL
--틀립(테이블 위친를 바꾸고 NOT IN을 사용하면 정답임)
select A.서비스ID
A.서비스명
A.서비스URL
from 서비스 A
where 서비스ID IN (select 서비스ID from 서비스이용
except
select 서비스ID from 서비스);
## 계층형 쿼리(=상속)
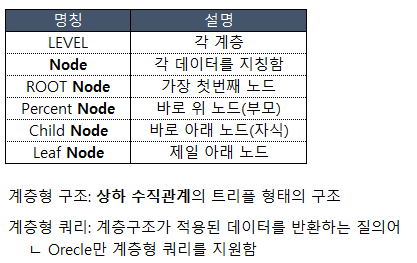
# 계층형구조 코딩방법
: ROOT(루트) Node(노드)의 기본값은 1임.
1번째 순서) START WITH 구문
- 계층의 루트로 사용될 행을 지정한다. 어떤 행을 최상위로 할지 결정한다.
- 서브쿼리 가능
2번째 순서) CONNECT BY + PRIOR 구문
- 연결고기를 만든다.
- PRIOR 연산사를 사용해서 계층구조를 표현.
- PRIOR 자식 = 부모(순방향) --> ex. PRIOR 부서번호 = 상위부서번호
순방향전개: 부모 노드로부터 자식 노드 방향으로 전개되는 것을 의미.
ㄴ 이전 LEVEL의 자식컬럼이 현재 행의 부모컬럼과 동일값이면, 현재행에서 이전 LEVEL의 +1로 계층을 세팅.
- PRIOR 부모 = 자식(역방향) --> ex. PRIOR 상위부서번호 = 부서번호 - 서브쿼리 사용불가
3번째 순서) order by LEVEL;
- 계층 구조 쿼리의 결과 DEPTH를 표현해준다.
- 계층형 쿼리에만 존재하는 컬럼이다.
# 계층형 질의문
- SQL server에서 계층형 질의문은 CTE(Common Table Expression)를 재 호출함을써 계층 구조를 전개한다.
ㄴ 공통테이블 표현식으로 사용됨(주로 with구문으로 사용) - SQL server에서 계층형 질의문은 앵커 맴버를 실행하여 기본 결과 집합을 만들고 재귀맴버를 지속적으로 실행한다.
- Oracle의 계층형 질의문에서 where절은 모든 전개를 진행한 이후, 필터조건으로 조건을 만족하는 데이터만 추출하는데 사용됨.
- SQL server의 계층형 질의문에서 PRIOR 키워드는 CONNECT BY 절에서만 사용할 수 있으며, 'PRIOR 자식=부모'형태로 사용하면, 순방향 전개로 수행된다.
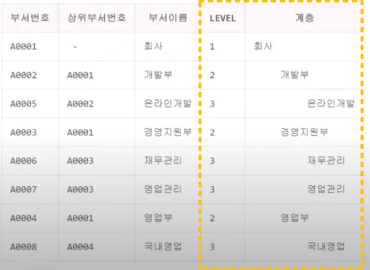
(예시1)

select 부서번호
, 상위부서번호
, 부서이름
, level
, LPAD('-', 5*(LEVEL-1)) || 부서이름 as 계층
from dept
START WITH 상위부서번호 is NULL --계층형 쿼리 최상단이므로 null값이 맞음
CONNECT BY PRIOR 부서번호 = 상위부서번호 --부서번호(자식) = 상위부서번호(부모) 가 순방향임
ORDER BY level; --계층구조 쿼리의 결과표현(계층형 쿼리에서만 사용됨)결과
(연습8) EMP테이블을 참조하여 SQL결과로 적절한 것은?(UNION ALL 문제)
select ENAME AAA, JOB AAB
from EMP
where EMPNO = 7369
UNION ALL
select ENAME BBA, JOB BBB
from EMP
where EMPNO = 7566
Order by 1,2;결과: 조회값 순서가 역순인 이유는 기본이 오름차순(ASC)이므로...

(연습8-1) UNION ALL과 UNION을 함께 사용하는 경우?

select COL1, COL2, count(*) as cnt
from ( select COL1, COL2 from TBL1
UNION ALL -- UNION ALL이 먼저 왔으므로 1순위 연산
select COL1, COL2 from TBL2
UNION -- UNION이 나중에 나왔으므로 2순위 연산
select COL1, COL2 from TBL1)
Group by COL1, COL2;** UNION ALL은 중복제거 안됨.
결과

(연습9) 계층구조에 2번째로 표시될 값을 구하시오.

select C3
from TBL1
start with C2 is NULL --ROOT노드는 최상위노드이며, 값은 기본으로 1임
connect by PRIOR C1=C2
order SIBLINGS by C3 DESC; --SIBLINGS는 동일한 노드 사이에서 정렬을 지정하는 구문. C3가 내림차순이므로 가장 먼저 나옴결과: C

(연습9) SQL 실행결과를 도출하시오.
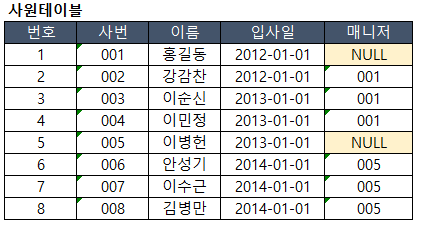
select 사번, 의름, 입사일, 매니저
from 사원
START WITH 매니저 is NULL
CONNECT BY PRIOR 사번 = 매니저 -- (순방향) PRIOR 자식 = 부모 순서
and 입사일 between '2013-01-01' and '2013-12-31'
order SIBLINGS by 사번정답: 계층구조상 최상위 매니저는 모두 출력되야 됨

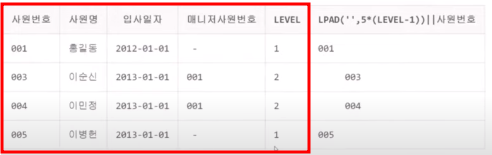
※ 계층구조 코드 확인 방법(테이블 3개이상 구조확인)
1번째 확인) START WITH 구문 먼저 파악 후,
2번째 확인) Connect by 절로 자식=부모 관계를 찾아가면 됨.
3번째 확인) 정렬은 DESC로 안하면, Order by절을 기준으로 ASC(작은숫자가 먼저 정렬)정렬 됨.
(연습10) 부서테이블 담당자 변경을 위해 SQL문을 작성하시오.
(단, 부서임시 테이블에서 변경일자 기준 최근 변경데이터 기준으로 부서테이블에 반영되야 됨)
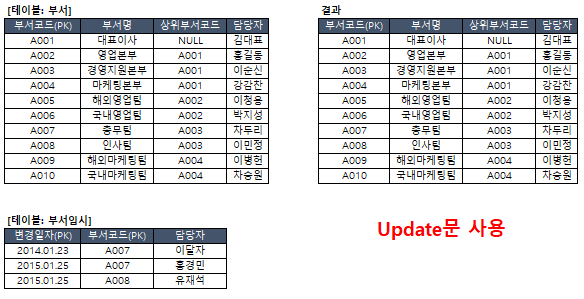
부서코드별로 MAX변경일자를 구하고 --> MAX변경일자에 맞는 담당자를 불러오기 위해
-- Oracle만 가능
--1안
UPDATE 부서 A
SET 담당자 = (select C.담당자
from (select 부서코드, MAX(변경일자) as 변경일자 -- 변경일자 Alisa 줘야 됨.
from 부서임시_102
group by 부서코드) B, 부서임시_102 C
where B.부서코드 = C.부서코드
and B.변경일자 = C.변경일자
and A.부서코드 = C.부서코드)
where 부서코드 in (select 부서코드 from 부서임시_102);
--2안
UPDATE 부서_102 A
SET 담당자 = (select B.담당자 --바로 담당자 호출형태
from 부서임시_102 B
where B.부서코드 = A.부서코드
and B.변경일자 = (select Max(C.변경일자) --서브쿼리 안에서 다시 MAX함수로 서브쿼리(변경일자 기준)
from 부서임시_102 C
where C.부서코드 = B.부서코드))
where 부서코드 in (select 부서코드 from 부서임시_102);** update문은 주의해서 사용해야 됨.
## VIEW 기능에 대해 다시한번 체크
- 정의만 갖고 있으며, 실행시점에 질의를 재작성하여 수행한다
- 복잡한 SQL문을 단순화 시켜주는 장점이 있으나, 테이블 구조가 변경되면 응용 프로그램은 변경 필요가 없음.
- 뷰는 보안강화를 위한 목적으로 사용될 수 있음.(실무에서는 뷰에 대한 권한만 줘서 업데이트 하도록 함)
- 실제 데이터를 정의하고 있는 뷰를 생성하는 기능을 지원하는 DBMS도 있음.(데이터 용량을 차지함)
(view 예시1) 보기의 뷰 생성 스크립트를 실행 후, 조회 SQL 실행결과를 작성하시오.
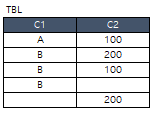
--[보기] view 생성 스크립티
select *from TBL_104
create view v_TBL
as
select * from TBL_014
where C1= 'B' or C1 is null;
-- [보기] 조회 SQL
select sum(C2) C2
from v_TBL
where C2 >=200 and C1 = 'B';결과: 200
'SQL' 카테고리의 다른 글
| [SQLD] 자격시험 - 학습 보강사항 4 (0) | 2024.01.04 |
|---|---|
| [SQLD] 자격시험 - 학습 보강사항 3 (0) | 2024.01.03 |
| [SQLD] 자격시험 - 학습 보강사항 1 (0) | 2023.12.30 |
| [Oracle] SQL, PLSQL - DB 백업, 저장(입력) 방식 (2) | 2023.12.06 |
| [Oracle] SQL, PLSQL 차이 (4) | 2023.11.29 |



