
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- SQLD 옵티마이저
- PLSQL
- JAVA 제어문
- SQLD 핵심포인트
- sqld 자격증
- sqld deny
- SQLD 자격시험 개념정리
- sqld trigger
- java string
- java 성별
- java Animal
- java 로또
- Java 메소드
- SQLD 특강
- java
- sqld remame
- java 단축키
- java 구구단
- SQL
- java 논리연산자
- Java Cat
- sqld grant
- java Fish
- JAVA for문
- java spider
- sqld 옵티마이져
- java 상속
- sqld revoke
- java 함수
- JAVA 연산자
- Today
- Total
SQLD, ECLIPS, JAVA,PYTHON, NODE....
[SQLD] 자격시험 - 학습 보강사항 4 본문
2024.1.4
(연습6) 아래 SQL구문의 결과를 작성하시오.

select A.사원ID, A.부서ID, A.사원명, A.연봉
from (select 사원ID, MAX(연봉) OVER(PARTITION BY 부서ID) AS 최고연봉
from 사원) A, 사원 Y
where A.사원ID = Y.사원ID
and A.최고연봉 = Y.연봉정답: 부서ID를 기준으로 연봉을 비교한 쿼리
| 사원ID | 부서ID | 사원명 | 연봉 |
| 002 | 100 | 강감찬 | 3000 |
| 003 | 200 | 김유신 | 4500 |
| 006 | 300 | 변사또 | 4500 |
# 윈도우함수 구분
LAG: 호출되는 테이블의 이전값(현재행 기준으로 바로 앞의 행을 표시하라는 의미)을 출력하는 명령어
LEAD: 호출되는 테이블의 이후행(현재행 기준으로 바로 뒤의 행을 표시하라는 의미)을 출력하는 명령어
(연습7) SQL 실행결과는?
| ID | Start_Val | End_Val |
| A | 10 | 14 |
| A | 14 | 15 |
| A | 15 | 15 |
| A | 15 | 18 |
| A | 20 | 25 |
| A | 25 |
create table TBL(
ID_varchar(10),
Start_Val number,
End_Val number )
select ID, Start_Val, End_Val
from ( select ID, Start_Val, NVL(End_Val, 99) End_Val,
(case when Start_Val = LAG(End_Val) OVER ( Partition BY ID -- LAG함수
Order by Start_Val, NVL(End_Val, 99) then 1
else 0
end) FLAG1,
(case when Start_Val = LEAD(Start_Val) OVER ( Partition BY ID -- LEAD함수
Order by Start_Val, NVL(End_Val, 99) then 1
else 0
end) FLAG2
from TBL)
where FLAG1 = 0
or FLAG2 = 0;결과: FLAG1과 FLAG2에서 0인 값을 갖는 테이블을 찾는거.
| ID | Start_Val | End_Val |
| A | 10 | 14 |
| A | 15 | 18 |
| A | 20 | 25 |
| A | 25 | 99 |
##권한부여, 권한 차단, 권한 회수
| GRANT | 유저에게 개체에 대한 권한을 허용(부여) with grant option : 권한을 부여받은 유저가 동일권한을 줄 수 있는 옵션 (형태) GRANT select ON SCHEMA:: A_User TO 유저명; |
| DENY | 유저에게 개체에 대한 권한을 차단 ( 근무자 퇴사하면 주로 사용함, 유저의 기록은 삭제 못함) (형태) DENY select ON SCHEMA:: A_User TO 유저명; --REVOKE와 동일한 권한회수 역할 DENY select ON A_User.Table1 TO 유저명; --유저에게 테이블 권한을 삭제 한다는 의미(REVOKE와 다름) |
| REVOKE | 유저에게 부여된 권한을 회수( 타부서 발령시 주로 사용) cascade: with grant option --> 부여된 권한까지 모두 회수 (형태) REVOKE select ON SCHEMA:: A_User FROM 유저명; |
(연습8) B_User에게 권한을 부여하는 DCL로 코드를 작성.
update A_User, TB_A
set col1 = 'AAA'
where col2 = 3;답안
GRANT select, UPDATE ON A_User.TB_A TO B_User;
(참고)
DBMS 사용자를 생성하면, 기본적으로 많은 권한을 부여해야 한다.
많은 DBMS에서는 DBMS관리자가 사용자별로 권한을 관리하는 부담과 복잡함을 줄이기 위해
다양한 권한을 그룹으로 묶어 관리할 수 있도록 사용자와 권한 사이에서
중개 역할을 수행하는 ROLL을 제공한다.
타부서에서 접근하거나 못하게 하도록 테이블별로 권한을 부여하기 위해
ROLL을 하나 만들어서 해당 권한에 대한 셋팅을 해둔 후,
계정을 생성할때 마다 ROLL 권한을 부여하면 된다.
(연습9) 우리팀에서 릴레이션 R을 생성한 후, 권한부여 SQL문을 실행 했을 경우 가능한 SQL문구는?
(단, A,B 데이터 값은 정수형)
| 우리팀 | |
| AIDEN | GRANT select, insert, delete ON R to LUCY with GRANT Option; |
| LUCY | GRANT select, insert, delete ON R TO Park; |
| AIDEN | REVOKE delect ON R from LUCY; |
| AIDEN | ROVOKE insert ON R from LUCY CASCADE; --Cascade는 권한을 모든 유저에게 회수시킴(LUCY와 Park) |
결과
Park: select *from R where A=400; --실행가능
park: delete from R where B=800; --실행가능
park: insert into R values(400,600); --불가
LUCY: insert into R values(500,700); --불가
## PL/SQL 작동 정의 (SQL을 확장한 절차적 명령어)
- 변수와 상수 등을 사용해서 일반 SQL문장을 실행할 때, where절의 조건으로 대입할 수 있다.
- procedure, user defined function, trigger 객체를 PL/SQL로 작성할 수 있다.
ㄴ 종류 3가지: procedure, Trigger, 함수
ㄴ 생성: create funtion, create trigger 로 만들 수 있음. - PL/SQL로 작성된 procedure, user defined function은 전체가 하나의 트랜젝션으로 처리되지 않아도 된다.
ㄴ 각각의 트렌젝션으로 처리 후, PL/SQL문으로 처리해도 된다.
ㄴ 호출문은 여러개 있으나, 주로 exec 테이블명; 로도 사용함. - procedure 내부에 작성된 절차적 코드는 PL/SQL 엔진이 처리하고 일반적인 SQL문장은 SQL 실행기가 처리한다.
(연습9) EMP테이블로부터, DEPT테이블에 데이터 입력하는 PL/SQL 문구를 보고 DEPT테이블에 데이터를 입력하기 전에
모든 데이터를 ROLLBACK이 불가능 하도록 삭제하는 코드를 작성하시오.
create or replace procedure
insert_dept authid current_user
as
begin
execute immediate 'TRUNCATE TABLE DEPT'; --oracle에선 execute immediate TRUNCATE를 사용해야 됨.
--create, drop, grant, revoke도 모두 동일하게 사용해야 됨.
insert into dept(deptno, dname, loc)
select deptno, dname, loc
from tmp_dept;
commit;
end;(해설)
동적 SQL처리를 위해 execute immediate 'TRANCATE TABLE DEPT'로 사용해야 되는 이유는
'TRANCATE TABLE DEPT'라는 변수로 담아서 사용해야 됨.
변수처리 없이 TRANCATE TABLE DEPT을 그대로 코딩하면, 작동하지 않음
## 절차형 SQL 모듈이란?
- 저장형 프로시저는 SQL을 로직과 함께 데이터베이스 내에 저장해 놓은 명령문의 집합.
- 저장형 함수(사용자 정의 함수)는 단독적으로 실행되기 보다
다른 SQL문을 통하여 호출되고
그 결과를 리턴하는 SQL의 보조적인 역할.
## 트리거(Trigger)
- 정의: 특정 테이블에 DBL(INSERT, UPDATE, DELETE)문이 수행되었을 때, 자동동작 하도록 작성된 프로그램.
즉, 데이터의 무결성과 일관성을 위한 사용자 정의 함수. - 데이터베이스에 의해 자동호출 되고 수행됨.
- 데이터베이스에서 로그인 작업에 주로 사용.
- TCL(commit / rollback / savepoint)을 이용하여 트렌젝션을 제어할 수 없음.
## 옵티마이저와 실행계획 (1~2문제 출제)
| Parser | Step1. 문법적, 의미적 오류 확인 Step2. SQL과 실행계획이 라이러리 캐시에 존재하는 확인 1) 존재하면 (soft parsing) --> SQL과 실행계획을 라이브러리 캐시에서 찾아 바로 실행 2) 존재하지 안으면(hard parsing) --> 옵티마이저를 거쳐서 쿼리비용 계산 후, 실행계획 생성. |
|
| Optimizer (DB 내부의 핵심엔진 역할) |
Query Transformer | 최적화 하기 쉽게 형태변환 시도. 논리적으로 변환 전/후 동일해야 됨. |
| Estimator | 실행계획에 대한 전체비용 계산. ( i/o, cpu, 메모리, 테이블 및 index 통계정보 확인) |
|
| Plan Generator | 후보군이 될 만한 실행계획 생성 | |
| Row source Generator | 실행할 수 이는 코드 형태로 포맷팅 | |
| SQL Engine | SQL 실행 | |
- SQL 처리 흐름도(실행 계획을 시각화 한 것)는 성능적인 측면의 표현을 우선 순위로 한다.
ㄴ 테이블의 엑세스 기법과 성능을 고려할 수 밖에 없다.
- 규직기반 옵티마이저에서 제일 높은 우선순위는 행에 대한 고유주소를 사용하는 방법이다.
ㄴ 우선순위 1번째는 ROW ID 임. 행(row)의 고유주소를 먼저 확인하기 때문.. - SQL처리 흐름도는 인덱스 스캔, 전체 테이블 스캔 등 엑세스 기법을 표현할 수 있다.
- 인덱스 범위 스캔은 여러 건의 결과가 반환되지 않음.
ㄴ 테이블에 결과가 없으면, 전체 테이블을 반환하기 때문에 결과값이 반드시 출력되긴 한다. - Oracle의 규칙기반 옵티마이저에서
가장 우선순위가 높은 규칙은 Single row by rowid 엑세스 기법이다.
ㄴ 테이블 전체를 호출하는 방식이 가장 마지막 순서.
- 비용기반 옵티마이저는 테이블, 인덱스, 컬럼 등 객체의 통계정보를 사용하여
실행계획을 수립하므로 통계정보가 변경되면, SQL의 실행계획이 달라질 수 있다.
- Oracle의 실행계획에 나타나는 기본적인 join 기법으로는 NLjoin, Hash Join, Sort Merge Join 이 있다.
- NL(Nested Loop) Join
ㄴ Online DP에 유용.
DW(대용량 데이터)의 데이터 집계업무에 사용하지 않음.
선택도가 낮은(결과 행의 수가 적은) 테이블이 선행 테이블로 선택되는 것이 일반적으로 유리.
ㄴ 조인 컬럼에 적당한 인덱스가 있어서 자연조인(Natural Join)이 효율적일 때 유용함.
ㄴ Driving Table 개념에 중요함.
특히, 조인 데이터 양에 큰 영향을 줌. --> Driving Table에서 컬럼수가 적을 수록 유리.
ㄴ Unique Index(EQUI) 활용,
수행시간이 적게 걸리는 소량 테이블을 온라인 조회하는 경우 유용.
ㄴ NL SEMI join은 특정조건 부합 시, 더 이상 연산하지 않는 join 기법 --> 성능에 유리, EXIST 사용
NL ANTI join은 특정조건 부합되지 않을 시, 연산하지 않은 Join 기법 --> 성능에 유리, NOT EXIST 사용 - Hash Join
ㄴ Sort Merge Join하기에 두 테이블이 커서 소트(sort)부하가 심할 때 사용.
ㄴ DW(대용량 데이터)에 유용
결과 행의 수가 작은 테이블을 선행 테이블로 사용하면, 성능에 유리하다.
즉, 작은 양의 테이블을 조인하는 경우 성능에 유리함.
ㄴ 조인 컬럼에 대한 인덱스가 없어 자연조인(Natual Join)이 비효율적일때 유용함.(NL join과 차이)
ㄴ 자연조인(Natual Join) 시, 드라이빙(Driving)집합 쪽으로 조인 엑세스량이 많아 Random 엑세스 부하가 심할때 사용.
ㄴ 정리가 잘 된 테이블을 Join할 때, 성능이 좋음.
ㄴ 메모리와 CPU를 많이 차지하는 join 기법임. - Sort Merge Join
ㄴ DW(대용량 데이터)에 유용
ㄴ 조인 컬럼에서 적당한 인덱스가 없어서 NL join이 비효율 적일 때 사용.
ㄴ Driving Table 개념이 중요하지 않은 조인 방식.
ㄴ 조인 조건의 인덱스의 유무에 영향이 없음.
ㄴ 등가와 비등가 조인과 관련 없음. --> 즉, 동등조인(Equi Join)과 비등가 조인 모두 사용 가능.
ㄴ Join key 컬럼이 잘 정리 되어 있으면, Hash Join보다 Sort Merge Join이 훨씬 유리함.
(연습) Join 기법은?
| [ DEPT 테이블 index 정보] PK DEPT : DEPTNO [EMP 테이블 index 정보] PK EMP : EMPNO IDX EMP 01: DEPTNO [SQL] select *from dept D where D.deptno = 'A001' and exist ( select 'X' from emp E where D.deptno = E.deptno |
결과: Nested Loop semi Join
(Orecle에서 not exist를 사용하면 semi join으로 인식함)
ㄴ exist와 not exist는 true or false만 판단.
이유: Nested Loop ANTI join은 NOT EXIST에서 사용. Nested Loop SEMI join은 EXIST에서 사용
# 옵티마이저 종류
| 규칙기반 | 미리 정해놓은 규칙에 따라 엑세스 경로평가, 실행계획 선택. 규칙: 경로별 우선순위 / index 구조 / 연산자 / 조건절 로 규칙별 실행. |
| 비용기반 (똑똑한 옵티마이저) |
쿼리 수행에 소요되는 일량, 시간을 비용으로 산정. 통계항목: 레코드 개수, 블록 개수, 하드웨어 속성 고려(cpu, i/O, 메모리) ==> CBO(Cost Base Optimizer) |
즉, 테이블 및 인덱스 등의 통계정보를 활용하여 SQL문을 실행하는데 소요될 처리시간 및 CUP, I/O 자원량 등을 계산하여
가장 효율적일 것으로 예상되는 실행계획을 선택하는 옵티마이저를 비용기반 옵티마이저(CBO) 라고 한다.
# 실행계획
- SQL처리를 위한 실행절차와 방법을 표현한 것
- 조인방법, 조인순서, 엑세스 기법 등이 표현됨.
- 동일 SQL문에 대해 실행계획이 다르면, 실행결과는 달라질 수 없다(실행결과는 모두 동일해야 됨)
ㄴ 하나의 SQL에서 실행계획은 다를 수 있음. - CBO(Cost Based Optimizer)의 실행계획에는 단계별 예상비용/건수 등이 표시 됨.
ㄴ 실제 비용/건수가 아닌, 예상되는 비용/건수를 표시하도록 되어 있다.
(참고) Oracle에선 SQL의 각 명령어별로 Excution Plan(엑세스 순서)을 알려준다.
즉, 엑세스 기법, 질의 처리 예상비용(cost), 조인 순서 알 수 있음.
단, 처리건수는 모름
(연습10) 실행계획 순서.
1 nested loops
2 hash join
3 table access(full) TBL1
4 table access(full) TBl2
5 table access(by rowid) TBL3
6 index(unique scan) pk TBL3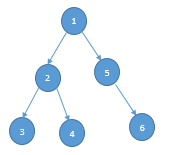
정답 : 3 --> 4 --> 2 --> 6 --> 5 --> 1
실행계획은 왼쪽 아래부터 실행됨을 명심.
## SQL 처리 흐름도(Access Flow Diagram)
- SQL은 실행시간을 알 수 없음
- 인덱스 스캔, 테이블 전체 스캔 등 같은 엑세스 기법이 표현 됨.
- 실제계획과 관련 있다.
- SQL의 내부적인 처리 절차를 시각적으로 표현해준다.
##관계형 데이터베이스의 인덱스(index)
- 인덱스 사용목적: 조회 성능을 최적화하는게 목적임.
ㄴ 단, DML(insert, update, delete 등) 처리 성능을 저하시킬 수 있음.
ㄴ DML작업은 주의해야 됨.
ㄴ insert와 Delete 작업과는 다르게 Update 작업에는 부하가 없을 수도 있음. - 기본 인덱스(Primary Key index)에 중복된 키 값들을 나타낼 수 없음.
ㄴ PK는 행을 구분해주는 키 값이므로, 중복되지 않으면서 NULL값은 있으면 안된다. - 인덱스에는 널 값(NULL value)이 나타날 수 없다.
- 인덱스로 데이터를 조회할 때,
인덱스를 구성하는 컬럼의 순서는 SQL 실행 성능에 밀접한 관계가 있다. - 자주 변경되지 않는 속성은 인덱스를 정의 할 좋은 후보이다.
- 테이블 전체 데이터를 읽는 경우엔 인덱스가 불필요.
- 인텍스는 조회, 삽입, 삭제, 갱신 연산의 속도를 저하된다.
ㄴ 소량의 데이터를 찾아가기 위해 사용하는 목적이므로~ 성능과 관련이 아주 깊다. - B-Tree Index는 관계형 데이터베이스의 주요 인덱스 구조.
ㄴ 브랜치블록과 리프블록으로 구성되며,
브랜치 블록은 분기를 목적으로 하고, 리프블록은 인덱스를 구성하는 컬럼의 값으로 정렬.
일반적으로 OLTP 시스템 환경에서 가장 많이 사용됨.
ㄴ 일치, 범위 검색에 적절하 구조(수직으로 구분하고, 맞으면 수평으로 구분하는 구조) - CLUSTERED Index는 인덱스의 리프 페이지가 곧 데이터 페이지이며,
리프 페이지의 모든 데이터는 인덱스 키 컬럼 순으로 물리적으로 정렬되어 저장된다.
ㄴ Oracle의 IOT와 매우 유사함. - BITMAP Index는 시스템에서 사용될 질의를 시스템 구현 시, 모두 알 수 없는 경우인 DW, AD-HOC 질의 환경을 위해 설계되었으며, 하나의 인덱스 키 엔트리가 많은 행에 대한 포인터를 저장하는 구조이다.
ㄴ byte 단위라서 가장 세밀한 인덱스 임. - 인덱스의 구성 컬럼에는 ASC(작은 값이 위로, 오름차순) or DESC(큰 값이 위로, 내림차순) 정렬을 정할 수 있음.
- 비용기반 옵티마이저는 인덱스 스캔이 항상 유리하다고 판단하고, 가장 똑똑한 인덱스 이다.
ㄴ cpu, i/o, 메모리 같은 하드디스크 적인 측면이나, 컬럼의 값 분포 등을 알아서 판단함. - 규칙기반(우선순위가 있음) 옵티마이저는 적절한 인덱스가 존재하면, 항상 인덱스를 사용하려고 한다.
ㄴ 인덱스 스캔이 풀 스캔보다 높은 우선순위에 있으므로~ - 인덱스 범위 스캔은 결과가 없으면, 한 건도 반환하지 않을 수 있다.
- 대량의 데이터를 삽입할때는 모든 인덱스를 생성하고 데이터를 입력하는 것이 좋지 않다.
ㄴ 데이터를 작업할 떄 인덱스가 있으면, 같이 작업을 해야 되기 때문에 데이터 정렬과 부하가 굉장히 심함.
ㄴ 데이터 이관작업 할때는 사용했던 인덱스를 모두 삭제하고 이관작업 완료 후, 새로 생성하는게 좋다. - 보조 인덱스(Secondary Index)에는 고유한 키 값이 아니여도 되고, 중복도 가능하다.
ㄴ 인덱스 설정할 때, unique설정을 안한다면 중복이 가능하다.
-- 코딩 형태 2가지
--1
create unique index 인덱스명 ON 테이블명(컬럼1, 컬럼2, ...)
--2
create index 인덱스명 ON 테이블명(컬럼1, 컬럼2, ...) -- secondary INDEX로 둘 수 있으므로 중복이 가능.
'SQL' 카테고리의 다른 글
| [SQLD] 자격시험 - 학습 보강사항 5(특강) - updated(Huge data) (2) | 2024.01.05 |
|---|---|
| [SQLD] 자격시험 - 학습 보강사항 3 (0) | 2024.01.03 |
| [SQLD] 자격시험 - 학습 보강사항 2 (2) | 2024.01.02 |
| [SQLD] 자격시험 - 학습 보강사항 1 (0) | 2023.12.30 |
| [Oracle] SQL, PLSQL - DB 백업, 저장(입력) 방식 (2) | 2023.12.06 |


